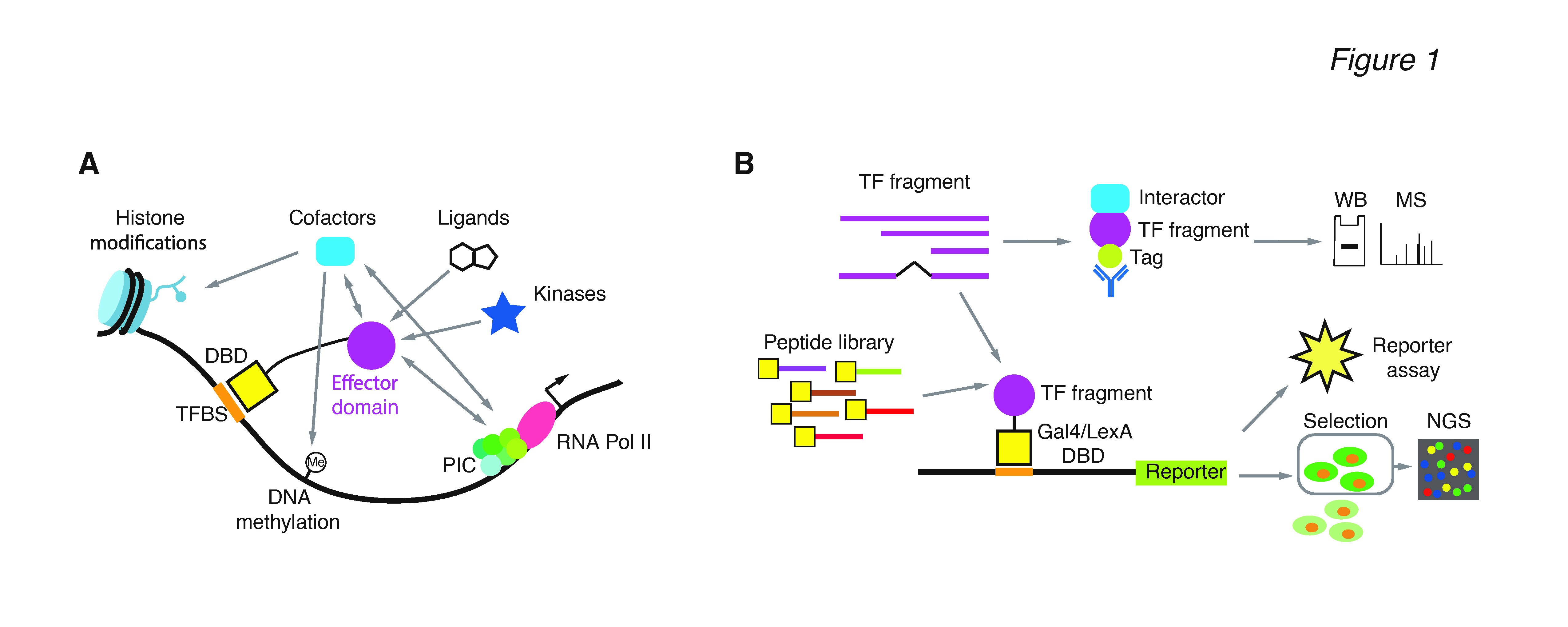
TFRegDB is a database of literature-curated 915 transcription factor (TF) effector domains corresponding to 596 human TFs.
The TFRegDB allows researchers to search for annotated effector domains with TF amino acid sequencesand to predict effector domains within an amino acid sequence using BLAST.
The TFRegDB website contains two main features: Search by TF and BLAST Search.
Search By TF Tutorial
Search by TF allows users to search through the transcription factors that are curated in the database.
Users can drag down and select (or type and select one of the auto fill results) the gene they are interested in on the search column on the left; the results will be shown on the right side under the 'Results' Tab.
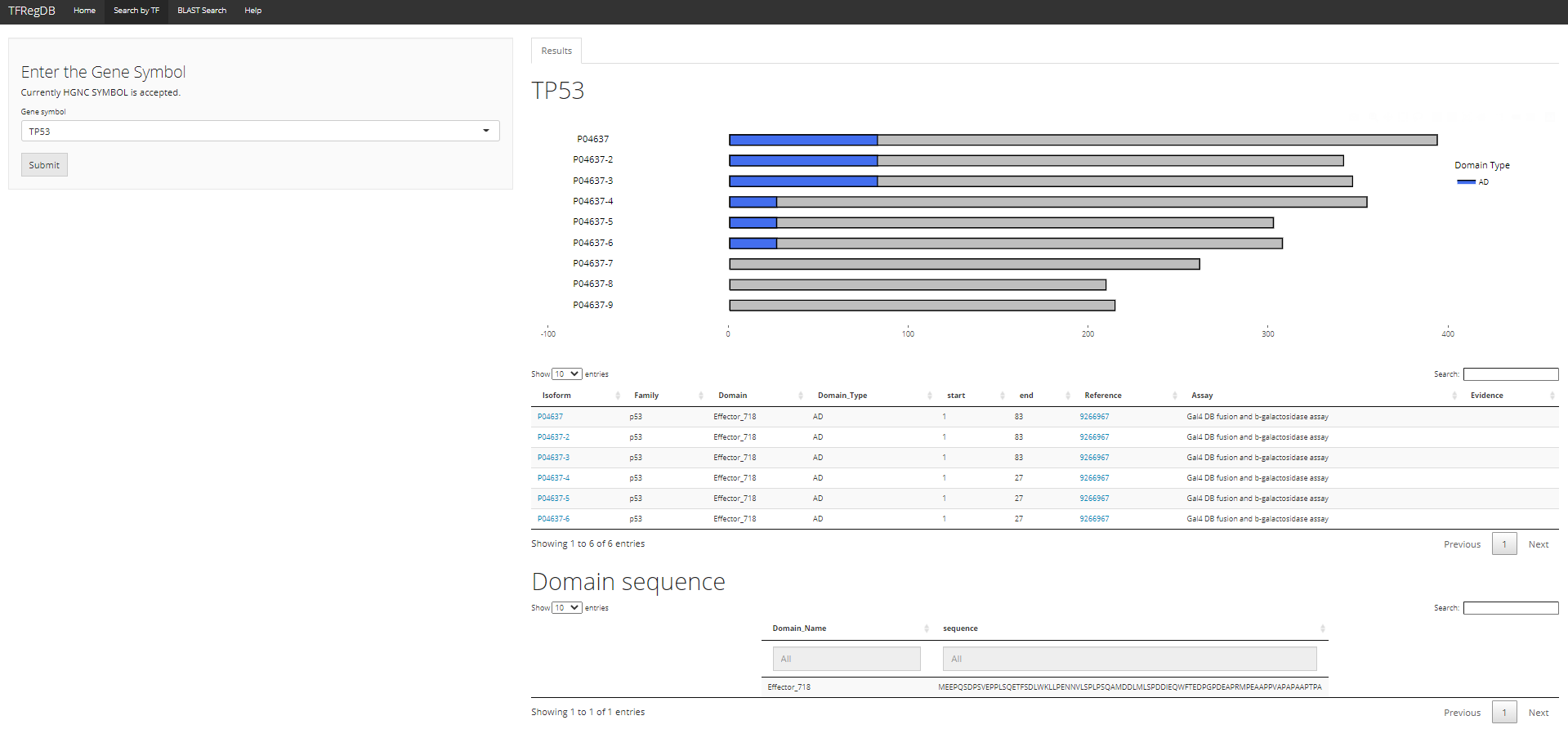
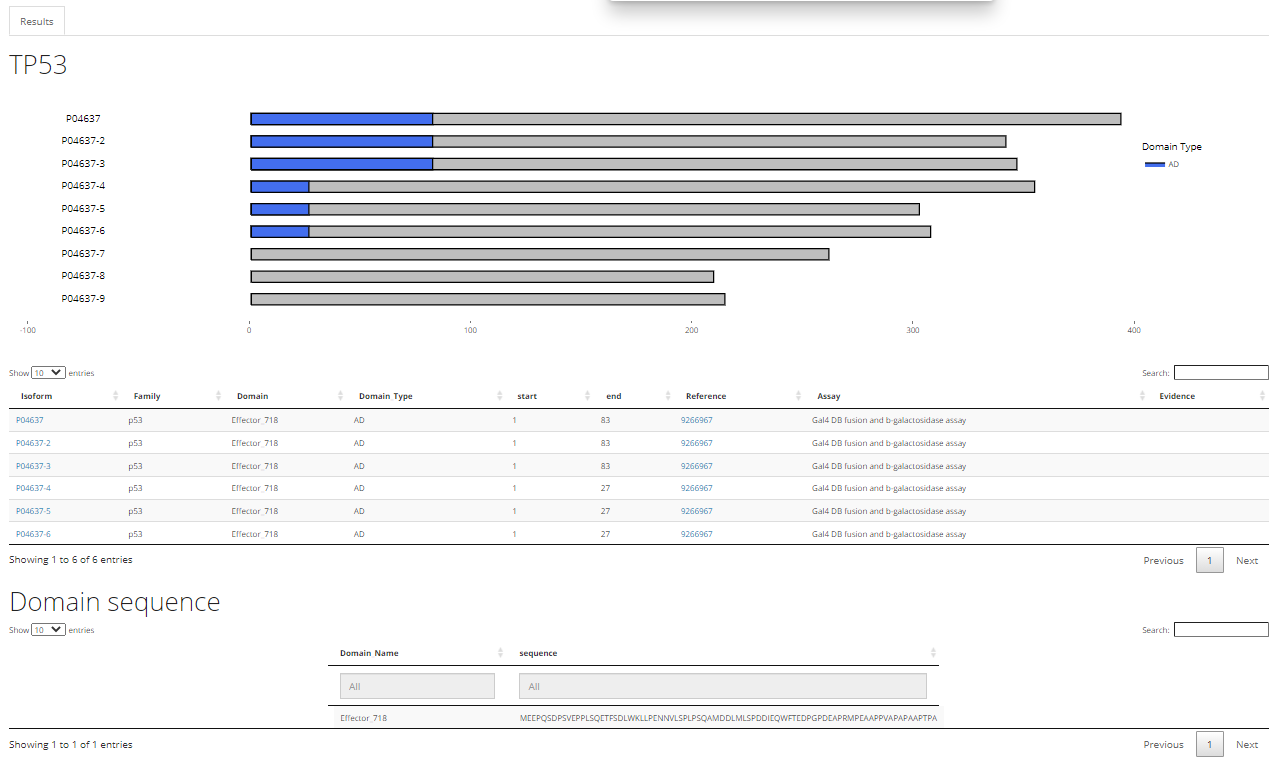
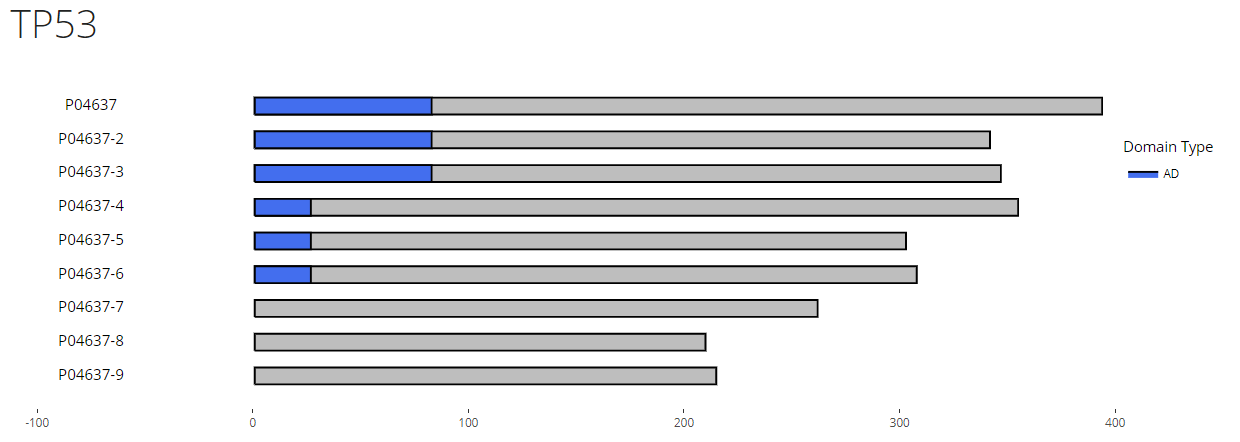
The results are divided into three sections: the visualization section, Detailed Results sections and Domain Sequence section as shown above.
The visualization section shows the location of domain(s) on different isoform of the same gene, and the Domain type (AD as activation domain, RD as repression domain and BiD as bifunctional domain) is shown by different colors: the blue is AD, red is RD and purple is BiD.
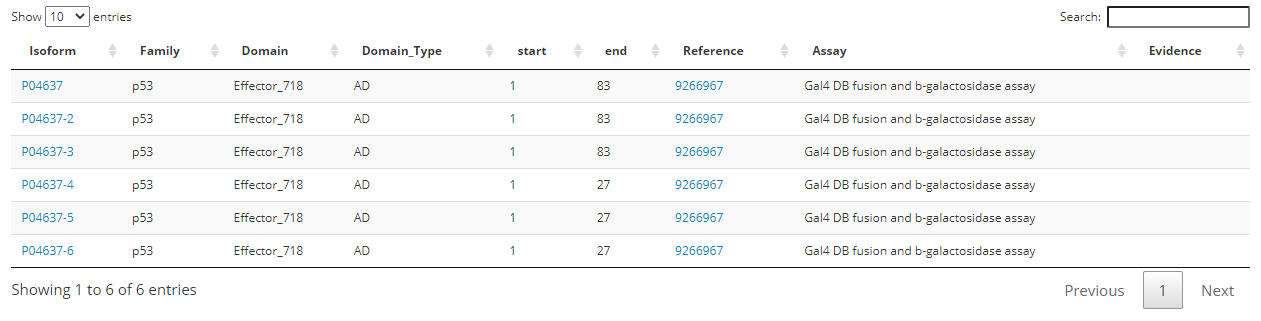
The Detail Results Section is a table with 7 columns.
The first and the second column are the isoform id and protein family.
The third and fourth column are the Domain ID and Domain Type, indicating whether the domain is activation domain, repression domain or bifunctional domain.
The fifth and sixth column is the start and end position of the domain on the isoform.
The seventh and eighth column are the literature reference id (PUBMED ID) and the experiment method that identified the presence of the domain.
The ninth column is the animal model used in the literature.
The tenth column indicates information about effector domains are reported as necessary(N), sufficient(S), or are not available.
The eleventh column is the activity level of effector domains reported in the literature. High(H), Medium(M), Low(L), or not available.
The twelfth column indicates the confidence score based on the (1) activity level, (2) if effector domains are necessary or sufficient, (3) other experimental evidence, and (4) if effector domains were obtained from other species. It could be High (H), Moderate(M), or Low (L).
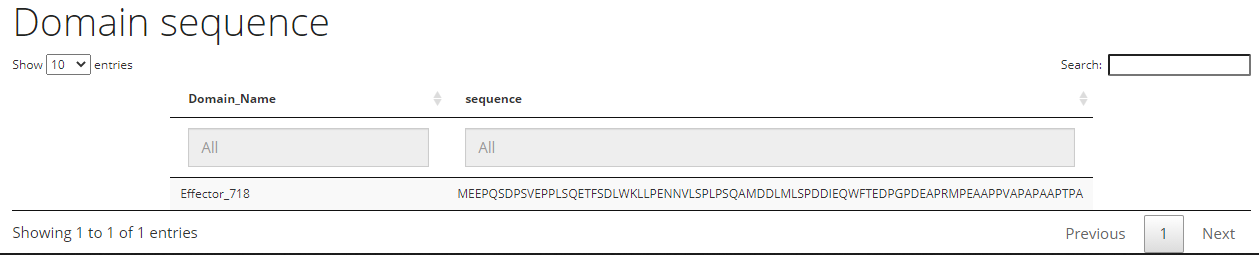
The Domain Sequence Section is a table of two columns. The first column is the domain id and the second column is the domain sequence.
BLAST Search Tutorial
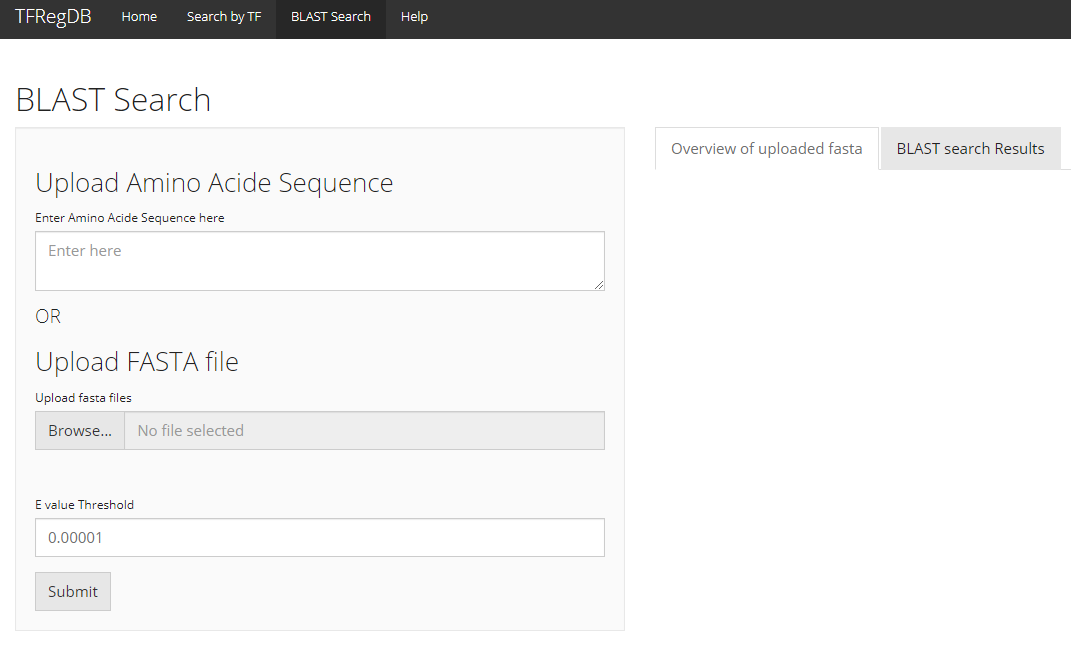
BLAST Search is aimed to search effector domains on proteins of interest by using BLAST against the effector domains Database.
Users can either enter a protein sequence or upload a FASTA file of protein sequence(s),
and then set an e-value threshold for the BLAST algorithm. The results will be shown on the right-hand side.
Results
There are two sections of the results: the Overview of uploaded FASTA section and BLAST search Results section.
Overview of uploaded FASTA File
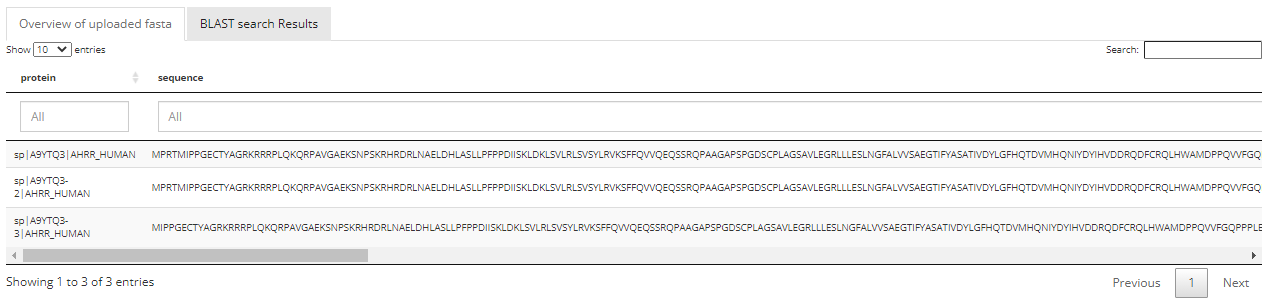
This section shows an overview of protein ID and protein sequence if user uploads a FASTA file. If user uses the type in method to submit the protein sequence the typed-in sequence will be shown in this section.
BLAST search Results
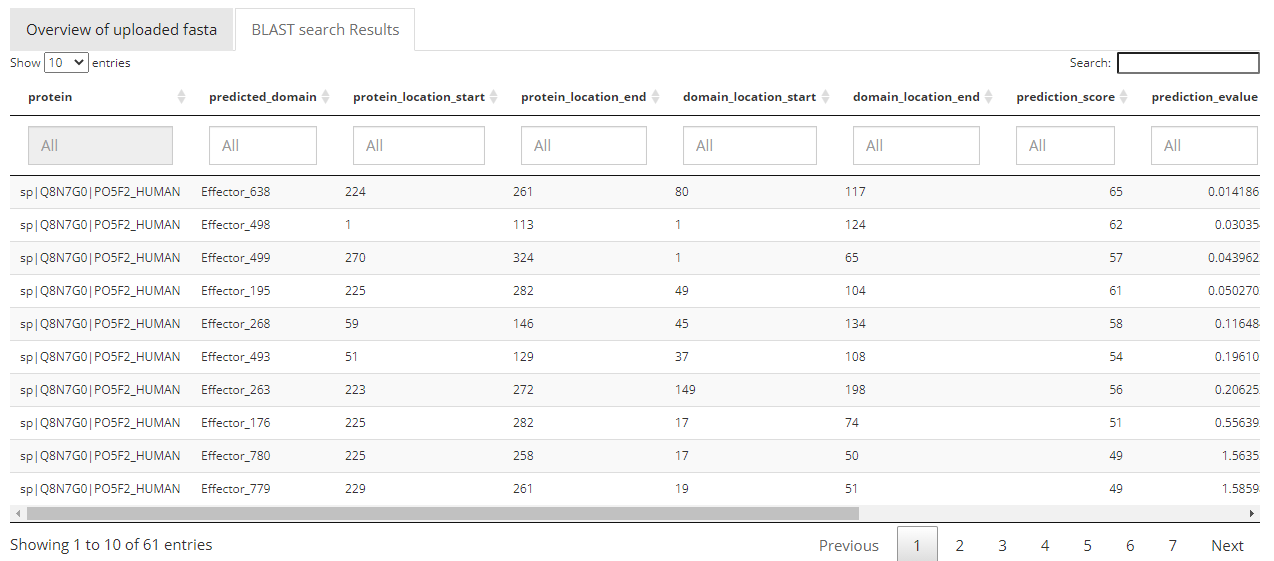
In this section the results will be shown in a table of 12 columns.
The first two columns show the protein ID and the domain id, indicating on which protein which domain is predicted to exist.
In the third and fourth column the coordinates (start and end) of the domains on the protein are shown.
The fifth and sixth column show the start and end position of the domain that aligned to the protein.
The seventh and eighth column are the e-value and the prediction score, the higher the prediction score and lower the e-value are, the more significant the prediction result is.
The ninth column shows the gene from which the domain is curated from (Detailed information can be obtained using the Gene Search Section).
The tenth column shows the type of the effector domain, it could be activation domain (AD), repression domain (RD) or bifunctional domain (Bif).
The eleventh and twelfth columns show the total length of the original domain and the fraction of domain predicted to be on the protein of interest.